Trixi-GPU
About Trixi-GPU
Trixi-GPU offers GPU acceleration for solving hyperbolic PDEs. The core solvers are based on the Trixi-Framework, with its acceleration powered by JuliaGPU. Currently, NVIDIA CUDA serves as our primary and experimental GPU acceleration support, and other types of GPU support will be implemented in the future.
TrixiCUDA.jl
TrixiCUDA.jl offers CUDA acceleration for solving hyperbolic PDEs on GPUs. It is our top-priority solution for achieving high acceleration in solving PDEs on GPUs.
Recent Update
Update on Jun 6, 2025:
The scalar indexing issue on GPU arrays has been fixed for most common examples, but for more complicated cases you can run them error‐free by doing
using CUDA; CUDA.allowscalar(true), and a permanent fix will be available soon.
Update on Mar 19, 2025:
The issue between the latest version of CUDA.jl and Trixi.jl has been resolved. The package is now compatible with CUDA.jl v5.7.0 and Trixi.jl v0.10 (see TrixiCUDA.jl PR #141).
Update on Jan 28, 2025:
It is recommended to update your Julia version to 1.10.8 (the latest LTS release) to avoid the issue of circular dependencies during package precompilation, which is present in Julia 1.10.7 (see issue).
Acceleration Overview
CPU and GPU Data Flow
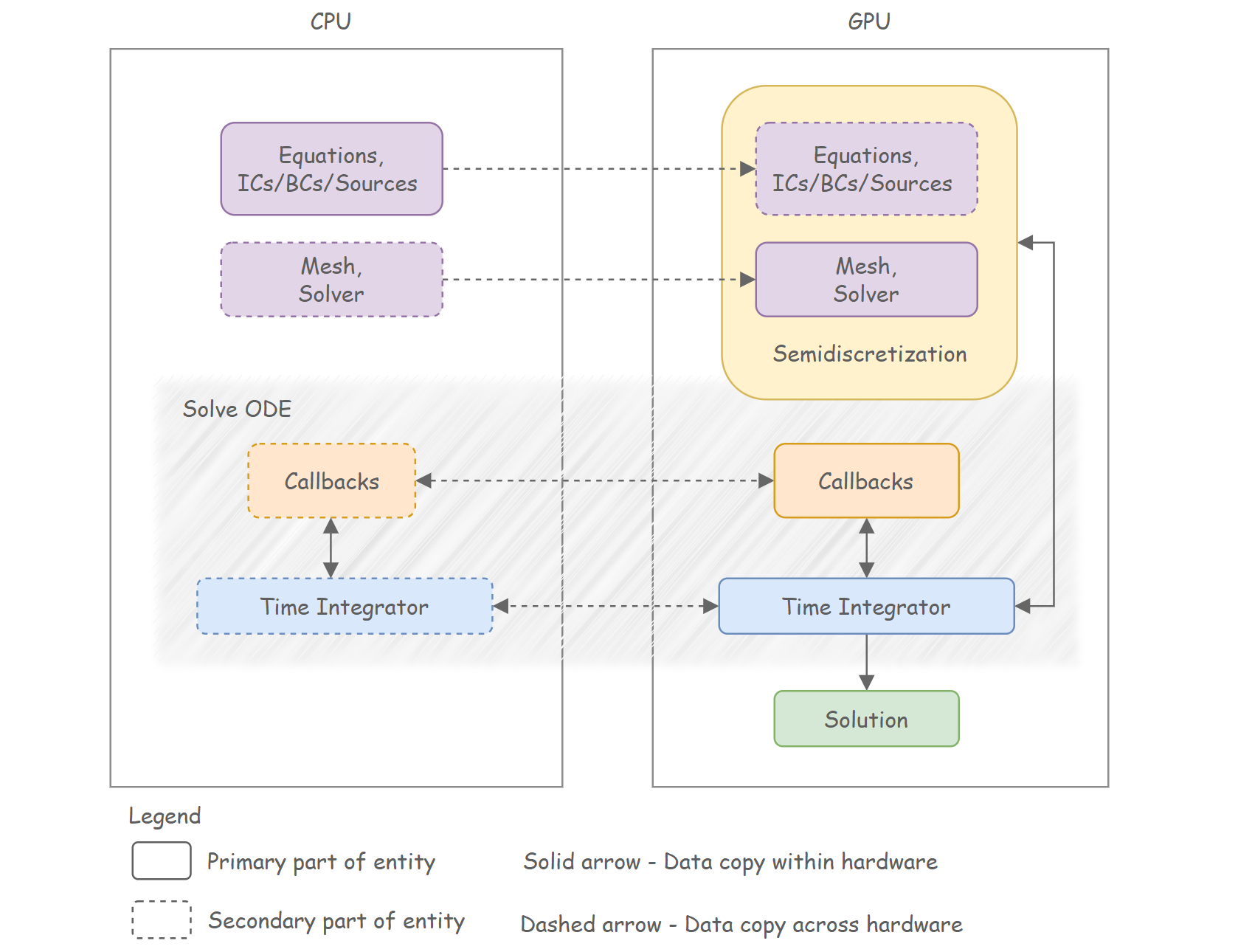
Minimizing large and frequent data transfers between the CPU and GPU is crucial for accelerating large programs. To reduce transfer overhead, initial values and large parameters are initialized and kept on the GPU throughout the solving process. Additionally, GPU-specific interfaces and custom kernels are implemented to speed up data initialization and processing.
ODE and PDE Acceleration
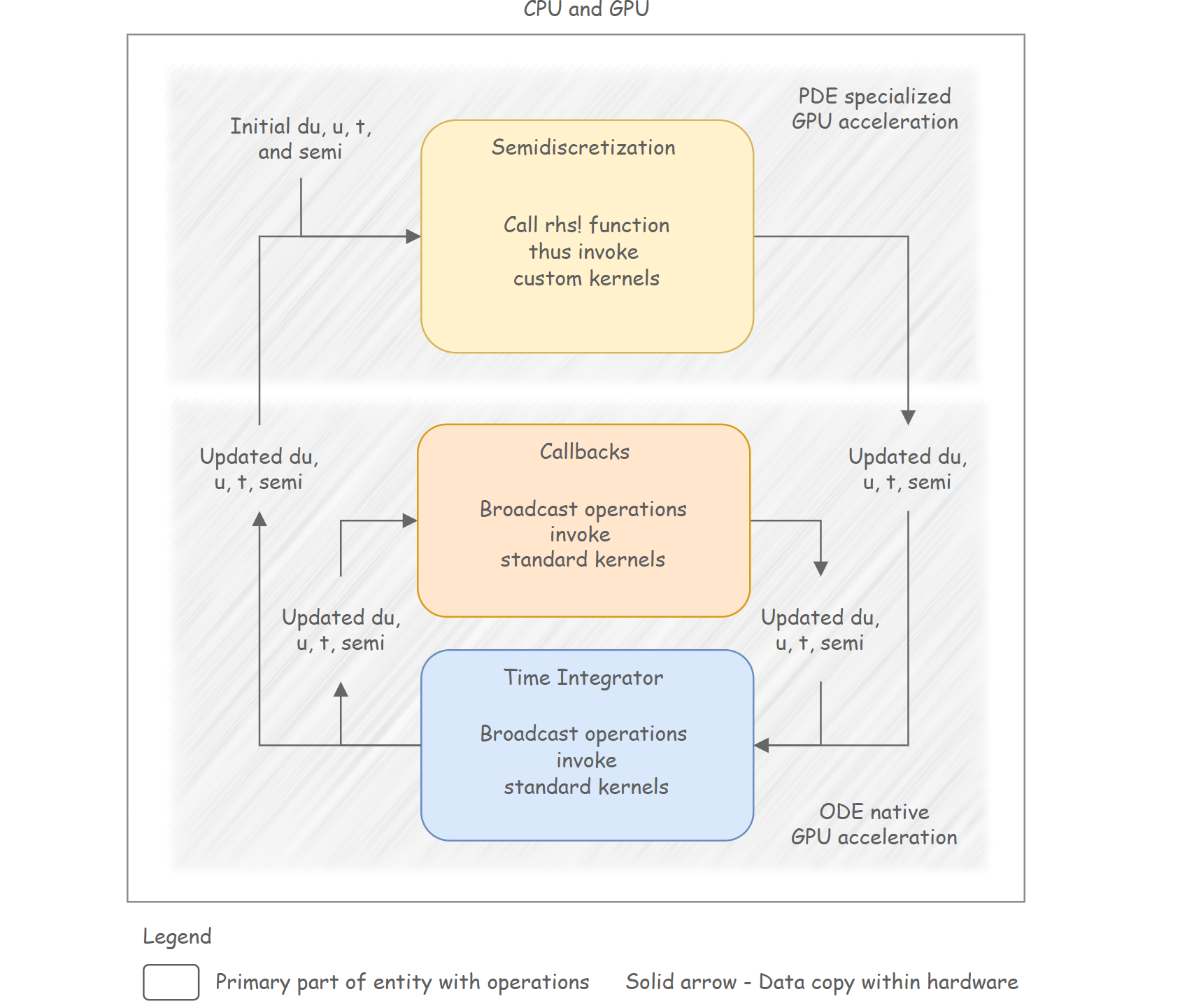
The overall GPU acceleration relies on two parts: (1) ODE acceleration, based on GPU array operations natively accelerated through CUDA.jl, and (2) PDE-specific acceleration, focusing on semidiscretization, implemented with custom kernels. With custom kernels, specialized optimizations focused on things like memory access and algorithms can be applied to achieve further speedup.
Smediscretization on GPU
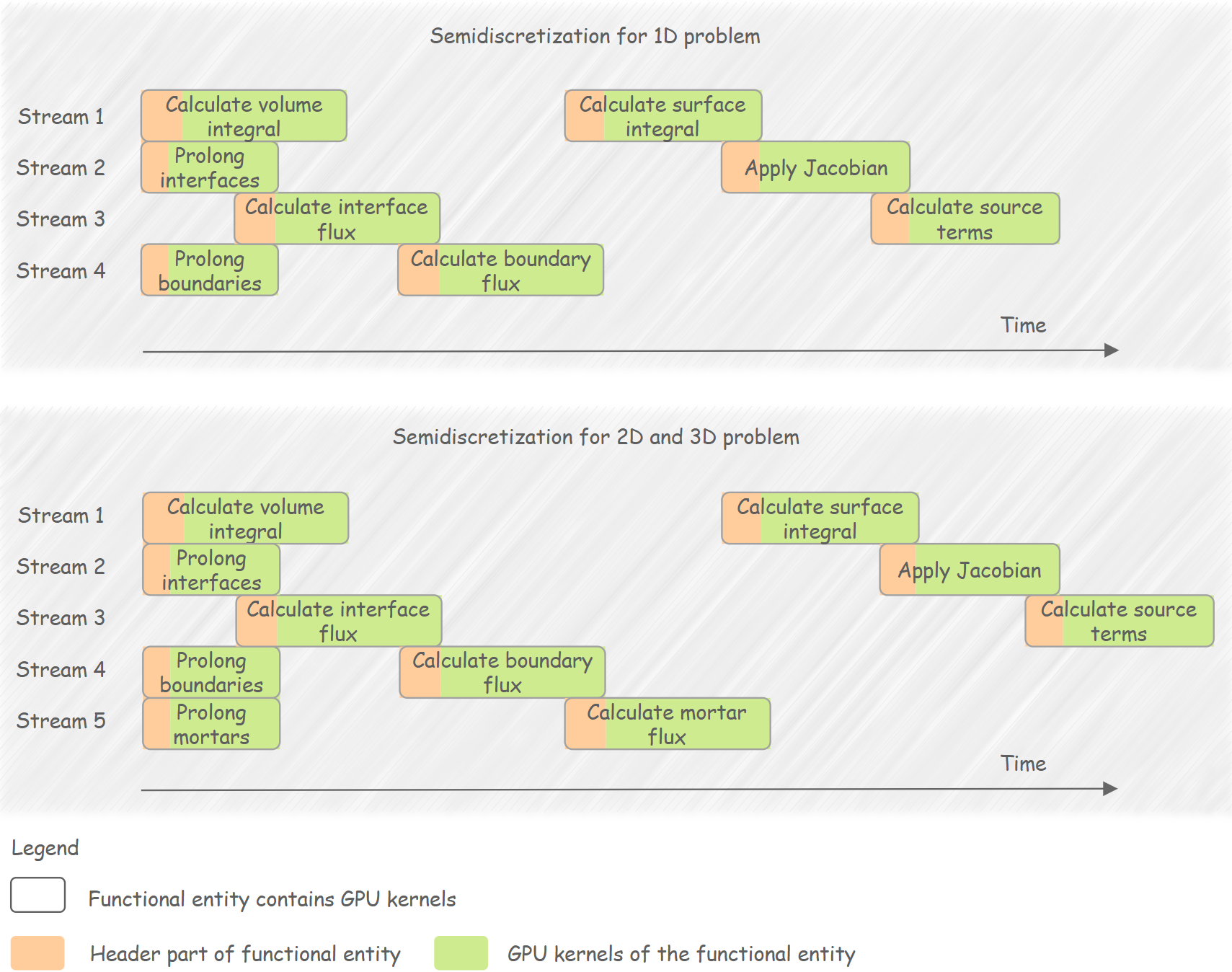
Semidiscretization is a key part of acceleration due to its potential for full parallelization and the weak data dependencies between some functionalities. Thus, running it on the GPU with pipelined streams is an effective approach to achieving high speedup. But some data dependencies force certain functionalities to remain sequential, making it hard to achieve more intensive pipelining.
News
There is a new project focused on implementing AMR with CUDA dynamic parallelism for the upcoming Google Summer of Code 2025. Please reach out if you are interested.
Acknowledgments
Thanks to our developers, maintainers, and outside contributors for their contributions to our community. Also, special thanks to Prof. Hendrik Ranocha, Prof. Jesse Chan, and Prof. Michael Schlottke-Lakemper for advising this project.
© Trixi-GPU developers. Powered by Franklin.jl and the Julia programming language.